Tìm hiểu về Outlier Detection – Khai thác dữ liệu và ứng dụng
I) Outlier là gì?
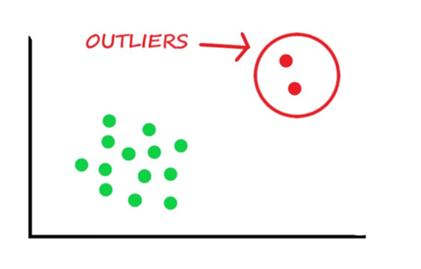
là một trong những thuật ngữ được sử dụng rất rộng rãi trong thế giới data và đặc biệt là data science. Xác định và loại bỏ outliers là một bước cực kỳ quan trọng trong quá trình xử lý dữ liệu. Việc xử lý các dữ liệu ngoại lai sẽ giúp tăng cao độ chính xác cho các mô hình dự đoán hay các báo cáo doanh nghiệp một cách đáng kể.
Outliers (dữ liệu ngoại lai) là các điểm dữ liệu bất thường khác biệt đáng kể so với phần còn lại của các mẫu. Chúng có thể xảy ra do lỗi trong quá trình thu thập dữ liệu hoặc chúng chỉ là các điểm dữ liệu hợp pháp và đại diện cho sự biến đổi tự nhiên.là một hoặc nhiều cá thể khác hẳn đối với các thành viên còn lại của nhóm. Sự khác biệt này có thể dựa trên nhiều tiêu chí khác nhau như giá trị hay thuộc tính,..
II) Các loại Outlier.
Các giá trị ngoại lai có thể có hai loại: đơn biến và đa biến . Có thể tìm thấy các giá trị ngoại lệ đơn biến khi xem xét sự phân bố các giá trị trong một không gian đối tượng địa lý. Các ngoại lệ đa biến có thể được tìm thấy trong không gian n chiều (trong số n đặc trưng). Nhìn vào sự phân bố trong không gian n chiều có thể rất khó đối với bộ não con người, đó là lý do tại sao chúng ta cần đào tạo một mô hình để làm điều đó cho chúng ta.
Các ngoại lệ cũng có thể có nhiều hương vị khác nhau, tùy thuộc vào môi trường: point outliers , contextual outliers hoặc collective outliers . Điểm ngoại lệ là các điểm dữ liệu đơn lẻ nằm xa phần còn lại của phân phối. Các ngoại lệ theo ngữ cảnh có thể là nhiễu trong dữ liệu, chẳng hạn như ký hiệu dấu chấm câu khi thực hiện phân tích văn bản hoặc tín hiệu nhiễu nền khi thực hiện nhận dạng giọng nói.
Chúng ta cùng điểm qua các hình ảnh các loại điểm outlier:
Left outlier
Là điểm ngoại lai có giá trị cực tiểu (extreamly low) trong mẫu quan sát.
Right outlier
Là điểm ngoại lai có giá trị cực đại (extreamly large) trong mẫu quan sát.
Representative outlier
Là một outlier trong tập dữ liệu. Trong đó, điểm dữ liệu này giả định rằng đã được quan sát đúng (thu thập và ghi chép số liệu chính xác) và các phần tử tương tự nó có thể tìm thấy trong quần thể. Nghĩa là, đây là một đại diện (representative) cho các outlier cùng thể loại khác và thường được giữ lại để phân tích. Ví dụ khi so sánh kích thước các loài động vật trong thiên nhiên, cá voi đại diện cho động vật có kích thước lớn, con chuột đại diện cho động vật có kích thước nhỏ.
Nonrepresentative outlier
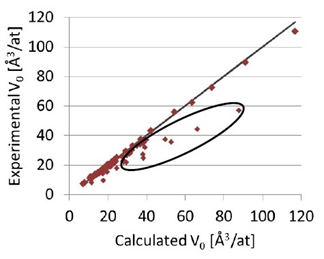
Là một outlier trong tập dữ liệu. Trong đó, nó chưa được quan sát một cách chính xác (sai sót trong quá trình thu thập và ghi chép dữ liệu) và được xem là duy nhất trong quần thể vì không tồn tại một giá trị nào tương tự như điểm dữ liệu này.
Alpha-trimmed mean

Alpha là giá trị trung bình của tập dữ liệu. Trong đó, 1/2 alpha trên và dưới của của tập dữ liệu sẽ bị loại bỏ.
Alpha-winsorized mean

Alpha là giá trị trung bình của tập dữ liệu. Trong đó, 1/2 alpha trên và dưới của tập dữ liệu sẽ được thay thế hoặc chuyển đổi sao cho phù hợp với tập dữ liệu hiện tại. Ví dụ ta có giá trị x1 (nhỏ nhất) đến x10 (lớn nhất). Hai giá trị này sẽ được thay thế bởi hai giá trị gần nó nhất là x2 và x9.
III) Các khó khăn trong việc phát hiện Outlier (Outlier detection)
Các nguyên nhân phổ biến nhất gây ra các giá trị ngoại lệ trên tập dữ liệu:
- Lỗi nhập dữ liệu (lỗi do con người)
- Sai số đo lường (lỗi thiết bị)
- Lỗi thử nghiệm (trích xuất dữ liệu hoặc lỗi lập kế hoạch / thực hiện thử nghiệm)
- Có chủ ý (các ngoại lệ giả được tạo ra để kiểm tra các phương pháp phát hiện)
- Lỗi xử lý dữ liệu (thao tác dữ liệu hoặc tập dữ liệu đột biến ngoài ý muốn)
- Lỗi lấy mẫu (trích xuất hoặc trộn dữ liệu từ các nguồn sai hoặc nhiều nguồn khác nhau)
- Tự nhiên (không phải lỗi, tính mới trong dữ liệu)
=> Vậy nên việc xác định Outliers là cần thiết trong phần lớn các trường hợp. Nhưng việc xử lý chúng như thế nào thì còn tùy thuộc vào từng hoàn cảnh. Chúng ta cần tìm hiểu sâu hơn nguyên nhân gây ra các Outliers trước khi quyết định loại bỏ hay giữ lại những outliers này để tránh những trường hợp sai xót không mong muốn.
Khi cố gắng phát hiện các ngoại lệ trong tập dữ liệu, điều rất quan trọng là phải ghi nhớ bối cảnh và cố gắng trả lời câu hỏi: “Tại sao tôi muốn phát hiện các ngoại lệ?” Ý nghĩa của những phát hiện của bạn sẽ được quyết định bởi ngữ cảnh. Từ đó chọn ra các phương pháp phát hiện ngoại lệ phù hợp
khi bắt đầu nhiệm vụ phát hiện ngoại lệ, bạn phải trả lời hai câu hỏi quan trọng về tập dữ liệu của mình:
Tôi đang tính đến những tính năng nào và bao nhiêu tính năng để phát hiện những điểm khác thường? ( đơn biến / đa biến )
Tôi có thể giả định (các) phân phối giá trị cho các đối tượng địa lý đã chọn của mình không? ( tham số / không tham số )
IV) Các phương pháp phát hiện Outlier. Trình bày có các nhóm phương pháp nào. Đặc trưng của từng nhóm. Mô tả sơ lược các phương pháp
- Các Nhóm
Vì bản chất của outliers có khá nhiều loại khác nhau nên cũng sẽ có nhiều phương pháp khác nhau để xác định outliers.
Có một vài hướng tiếp cận để phát hiện các điểm ngoại lai. Trong cuốn sách Outlier Analysis của Charu Aggarwal, tác giả phân loại các mô hình phát hiện các điểm ngoại lai thành các nhóm như sau:
- Z-Score or Extreme Value Analysis (parametric): đây là dạng cơ bản nhất để phát hiện các điểm ngoại lai và chỉ tốt cho dữ liệu 1 chiều. Trong mô hình phân tích này, ta giả định các giá trị nào quá lớn hay quá nhỏ đều là ngoại lai. Các phương pháp Z-test và Student’s t-test là ví dụ cho các mô hình thống kê này. Tuy nhiên, mô hình này không thật sự mạnh khi phân tích trên các điểm dữ liệu nhiều chiều (multivariate). Mô hình này thường được sử dụng ở bước cuối trong quá trình diễn giải kết quả nghiên cứu và phân tích.
- Probabilistic and Statistical Models (PCA, LMS): ta áp đặt một phân bố cụ thể cho tập dữ liệu (normal distribution, Bernoulli distribution, poisson distribution, ..). Sau đó, ta sử dụng phương pháp expectation-maximization(EM) để ước lượng tham số cho các mô hình thống kê này. Cuối cùng, ta tính xác suất cho các phần tử thuộc tập dữ liệu ban đầu. Các phần tử nào có xác suất thấp sẽ được cho là điểm ngoại lai.
- Linear Models (non-parametric): phương pháp này chuyển đổi tập dữ liệu ban đầu sang không gian ít chiều hơn (sub-space) bằng cách sử dụng tương quan tuyến tính (linear correlation). Sau đó, khoảng cách của từng điểm dữ liệu đến mặt phẳng ở không gian mới sẽ định tính toán. Khoảng cách tính được này được dùng để tìm ra các điểm ngoại lai. PCA (Principal Component Analysis) là ví dụ của linear models để xác định các điểm ngoại lai.
- Proximity-based Models (non-parametric): ý tưởng của phương pháp này là mô hình hóa các điểm ngoại lai sao cho chúng hoàn toàn tách biệt (isolated) khỏi toàn bộ các điểm dữ liệu còn lại. Cluster analysis, density based analysis và nearest neighborhood là các hướng tiếp cận chính của phương pháp này.
- Information Theoretic Models: ý tưởng của phương pháp này là dựa trên nguyên lý các điểm ngoại lai sẽ làm tăng giá trị minimum code length khi mô tả tập dữ liệu.
- High-Dimensional Outlier Detection (high dimensional sparse data): phương pháp đặc biệt để xử lý các tập dữ liệu nhiều chiều và rời rạc (high dimensional sparse data). Ví dụ, ta có phương pháp High Contrast Subspaces for Density-Based Outlier Ranking (HiCS).
- Đặc trưng của từng nhóm.
Chúng ta cùng điểm qua sơ lược một số phương pháp phát hiện ngoại lệ:
Z-Score
z-score hoặc điểm chuẩn của một quan sát là số liệu cho biết điểm dữ liệu có bao nhiêu độ lệch chuẩn so với giá trị trung bình của mẫu, giả sử là phân phối gaussian. Điều này làm cho điểm số z trở thành một phương pháp tham số. Rất thường xuyên các điểm dữ liệu không được mô tả bằng phân phối gaussian, vấn đề này có thể được giải quyết bằng cách áp dụng các phép biến đổi cho dữ liệu, tức là: chia tỷ lệ nó.
Một số thư viện Python như Scipy và Sci-kit Learn có các hàm và lớp dễ sử dụng để triển khai dễ dàng cùng với Pandas và Numpy.
Sau khi thực hiện các chuyển đổi thích hợp đối với không gian đặc trưng đã chọn của tập dữ liệu, điểm số z của bất kỳ điểm dữ liệu nào có thể được tính bằng biểu thức sau:
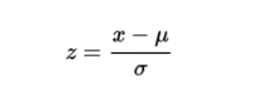
Khi tính toán điểm số z cho mỗi mẫu trên tập dữ liệu, một ngưỡng phải được chỉ định. Một số ngưỡng ‘quy tắc ngón tay cái’ tốt có thể là: độ lệch chuẩn 2,5, 3, 3,5 hoặc nhiều hơn.
Bằng cách ‘gắn thẻ’ hoặc xóa các điểm dữ liệu vượt quá ngưỡng nhất định, chúng tôi đang phân loại dữ liệu thành các điểm ngoại lệ và không ngoại lệ
Điểm số Z là một phương pháp đơn giản nhưng mạnh mẽ để loại bỏ các ngoại lệ trong dữ liệu nếu bạn đang xử lý các phân phối tham số trong không gian đặc trưng có chiều thấp. Đối với các vấn đề phi tham số, Dbscan và Isolation Forests có thể là những giải pháp tốt.
Dbscan (Phân cụm không gian dựa trên mật độ của các ứng dụng có tiếng ồn)
Trong học máy và phân tích dữ liệu, phương pháp phân nhóm là những công cụ hữu ích giúp chúng ta hình dung và hiểu dữ liệu tốt hơn. Mối quan hệ giữa các đối tượng địa lý, xu hướng và quần thể trong tập dữ liệu có thể được biểu diễn bằng đồ thị thông qua các phương pháp phân nhóm như dbscan và cũng có thể được áp dụng để phát hiện các điểm khác biệt trong phân phối không đối xứng theo nhiều chiều.
Dbscan là một thuật toán phân cụm dựa trên mật độ, nó tập trung vào việc tìm kiếm các lân cận theo mật độ (MinPts) trên một ‘hình cầu n chiều’ với bán kính ɛ. Một cụm có thể được định nghĩa là tập hợp tối đa các ‘điểm được kết nối mật độ’ trong không gian đối tượng địa lý.
Sau đó, Dbscan xác định các lớp điểm khác nhau:
- Điểm quặng C : A là điểm cốt lõi nếu vùng lân cận của nó (được xác định bởi ɛ) chứa ít nhất cùng một số hoặc nhiều điểm hơn tham số MinPts.
- Điểm biên giới : C là điểm biên giới nằm trong một cụm và vùng lân cận của nó không chứa nhiều điểm hơn MinPts, nhưng nó vẫn có ‘ mật độ có thể truy cập được’ bởi các điểm khác trong cụm.
- Outlier : N là một điểm outlier rằng sự dối trá trong không cluster và nó không phải là ‘ mật độ có thể truy cập’ cũng không ‘ mật độ kết nối’ để bất kỳ điểm nào khác. Vì vậy, điểm này sẽ có “cụm riêng của mình”.

Nếu A là một điểm cốt lõi, nó tạo thành một cụm với tất cả các điểm có thể truy cập được từ nó. Một điểm Q có thể đến được từ P nếu có một đường dẫn p1,…, pn với p1 = p và pn = q , trong đó mỗi pi + 1 có thể truy cập trực tiếp từ pi (tất cả các điểm trên đường đi phải là điểm cốt lõi, với ngoại lệ có thể có của q ).
Khả năng tiếp cận là một quan hệ không đối xứng vì theo định nghĩa, không có điểm nào có thể đạt được từ điểm không phải cốt lõi, bất kể khoảng cách (vì vậy, điểm không phải lõi có thể đạt được, nhưng không thể đạt được gì từ điểm đó!). Do đó, cần có thêm một khái niệm về tính kết nối để xác định chính thức mức độ của các cụm được tìm thấy bởi thuật toán này.
Hai điểm p và q được nối mật độ với nhau nếu có một điểm o sao cho cả p và q đều có thể đạt tới mật độ từ o . Mật độ kết nối là đối xứng.
Một cụm thỏa mãn hai thuộc tính:
- Tất cả các điểm trong cụm được kết nối với nhau theo mật độ.
- Nếu một điểm có thể tiếp cận theo mật độ từ bất kỳ điểm nào của cụm thì nó cũng là một phần của cụm.
Sci-kit Learn có triển khai dbscan có thể được sử dụng dọc theo gấu trúc để xây dựng mô hình phát hiện ngoại lệ.
Một lần nữa, bước đầu tiên là chia tỷ lệ dữ liệu, vì bán kính ɛ sẽ xác định các vùng lân cận cùng với MinPts . (Mẹo: một công cụ mở rộng tốt cho vấn đề đang xảy ra có thể là Scaler Robust Scaler của Sci-
kit Learn ).
Sau khi mở rộng không gian đối tượng, đã đến lúc chọn số liệu không gian mà trên đó dbscan sẽ thực hiện phân nhóm. Số liệu phải được chọn tùy thuộc vào vấn đề, số liệu euclide hoạt động tốt cho 2 hoặc 3 thứ nguyên, số liệu manhattan cũng có thể hữu ích khi xử lý các không gian đối tượng có chiều cao hơn 4 thứ nguyên trở lên.
Sau đó, tham số eps (ɛ) phải được chọn tương ứng để thực hiện phân cụm. Nếu ɛ quá lớn, nhiều điểm sẽ được kết nối với nhau theo mật độ, nếu quá nhỏ thì việc phân cụm sẽ tạo ra nhiều cụm vô nghĩa. Một cách tiếp cận tốt là thử các giá trị nằm trong khoảng từ 0,25 đến 0,75.
Dbscan cũng nhạy cảm với tham số MinPts, việc điều chỉnh nó sẽ hoàn toàn phụ thuộc vào vấn đề hiện tại.
Độ phức tạp của dbscan là O ( n log n ), nó và phương pháp hiệu quả với các tập dữ liệu có kích thước trung bình. Việc cung cấp dữ liệu vào mô hình rất dễ dàng khi sử dụng triển khai của Scikit learning. Sau khi lắp dbscan vào các cụm dữ liệu có thể được trích xuất và mỗi mẫu được gán cho một cụm. Dbscan tự ước tính số lượng cụm, không cần chỉ định số lượng cụm mong muốn, nó là một mô hình học máy không giám sát.
Các giá trị ngoại lai (nhiễu) sẽ được gán cho cụm -1. Sau khi gắn thẻ các trường hợp đó, chúng có thể được xóa hoặc phân tích.
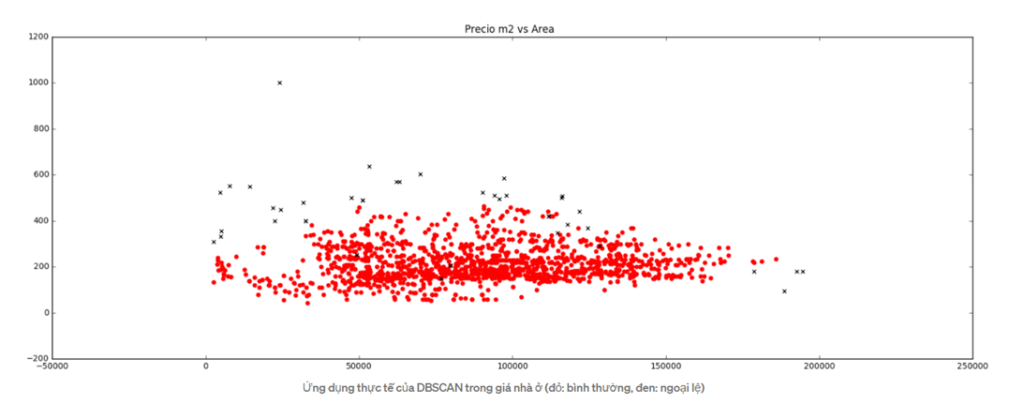
Isolation Forests

Cuối cùng nhưng không kém phần quan trọng, rừng cách ly là một phương pháp hiệu quả để phát hiện những điểm khác thường hoặc tính mới trong dữ liệu. Đây là một phương pháp tương đối mới dựa trên cây quyết định nhị phân. Cách triển khai của Sci-Kit Learn tương đối đơn giản và dễ hiểu.
Nguyên tắc cơ bản của rừng cách ly là số lượng ngoại lai là rất ít và khác xa so với phần còn lại của các quan sát.Để xây dựng một cây (đào tạo), thuật toán chọn ngẫu nhiên một đối tượng từ không gian đối tượng và một giá trị phân chia ngẫu nhiên khác nhau giữa giá trị tối đa và tối thiểu. Điều này được thực hiện cho tất cả các quan sát trong tập huấn luyện. Để xây dựng khu rừng, một quần thể cây được thực hiện lấy trung bình tất cả các cây trong rừng.
Sau đó, để dự đoán, nó so sánh một quan sát với giá trị phân tách đó trong một “nút”, nút đó sẽ có hai nút con mà trên đó sẽ thực hiện một phép so sánh ngẫu nhiên khác. Số lượng “phần tách ” được thực hiện bởi thuật toán cho một ví dụ được đặt tên là: ” độ dài đường dẫn “. Như mong đợi, các giá trị ngoại lai sẽ có độ dài đường đi ngắn hơn so với các quan sát còn lại.
Điểm ngoại lệ có thể được tính cho mỗi lần quan sát:
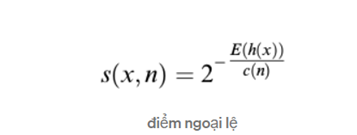
Trong đó h (x) là độ dài đường dẫn của mẫu x và c (n) là ‘độ dài tìm kiếm không thành công’ của cây nhị phân (độ dài đường dẫn tối đa của cây nhị phân từ nút gốc đến nút bên ngoài) n là số các nút bên ngoài. Sau khi cho điểm mỗi quan sát từ 0 đến 1; 1 nghĩa là ngoại lai hơn và 0 nghĩa là bình thường hơn. Một ngưỡng có thể được chỉ định (ví dụ: 0,55 hoặc 0,60)
V) Trình bày 1 phương pháp để trinh bày chi tiết.
Em sẽ sử dụng phương pháp Extreme Value Analysis. Phương pháp này đơn giản là xác định các data points có giá trị cực cao/thấp (extreme value). Các giá trị extreme sẽ được xác định bằng khoảng cách của chúng so với giá trị trung bình (Average/Mean).
Phân vị

Phân vị là một thước đo được sử dụng trong thống kê cho biết giá trị mà dưới đó tỷ lệ phần trăm quan sát nhất định trong một nhóm quan sát giảm xuống. Ví dụ: phân vị thứ 20 là giá trị dưới 20% số quan sát có thể được tìm thấy. Tương tự, 80% các quan sát được tìm thấy trên phân vị thứ 20.
Kiểm tra phần trăm tối đa
Bây giờ chúng ta hãy sử dụng phương pháp lượng tử sẽ cung cấp các giá trị ngưỡng tối đa và tối thiểu từ tập dữ liệu.
Thực hiện để tìm giá trị ngưỡng tối thiểu từ cột chiều cao.

Có một giá trị có hơn 95% giá trị có nghĩa là điểm dữ liệu lỗi.
hãy kiểm tra hàng đó

Chúng ta có thể thấy chiều cao của imran là hơn 14 feet và đó không phải là tất cả, chúng ta kiếm tra tiếp
Kiểm tra phần trăm tối thiểu
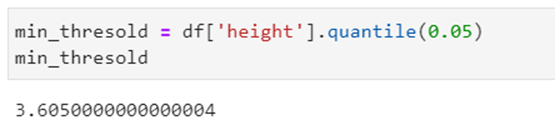
Kiểm tra giá trị
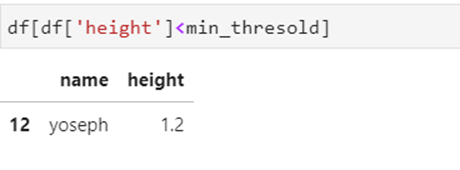
Yoseph có độ cao 1,2 feet và một lần nữa điều đó là không thể, vì vậy bây giờ hãy để loại bỏ hai ngoại lệ này khỏi tập dữ liệu.
Loại bỏ các ngoại lệ này

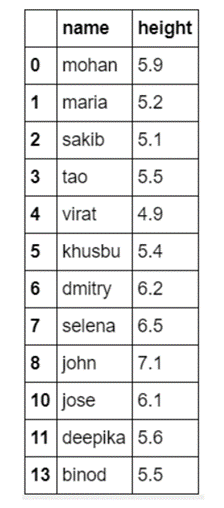
Điều này rất dễ dàng tìm thấy ở các ngoại lệ từ tập dữ liệu nhỏ, bây giờ chúng ta hãy làm điều đó trên tập dữ liệu phức tạp.
Dữ liệu này lấy từ Kaggle , tập dữ liệu về giá nhà của thành phố Bengaluru từ Ấn Độ.
Nhập tập dữ liệu và kiểm tra các cột


Xem số dòng số cột của dữ liệu

Tóm tắt lại các cột:
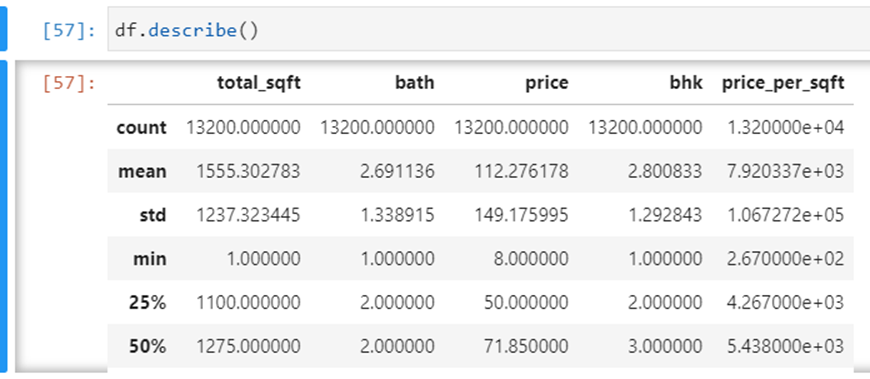

Bây giờ hãy kiểm tra ngưỡng tối thiểu và tối đa

Đầu tiên, hãy kiểm tra điểm dữ liệu ngưỡng tối thiểu.

Bây giờ một lần nữa bạn có thể thấy hàng có 371 price_per_sqft 3 BHK.
bây giờ, hãy kiểm tra điểm dữ liệu ngưỡng tối đa.
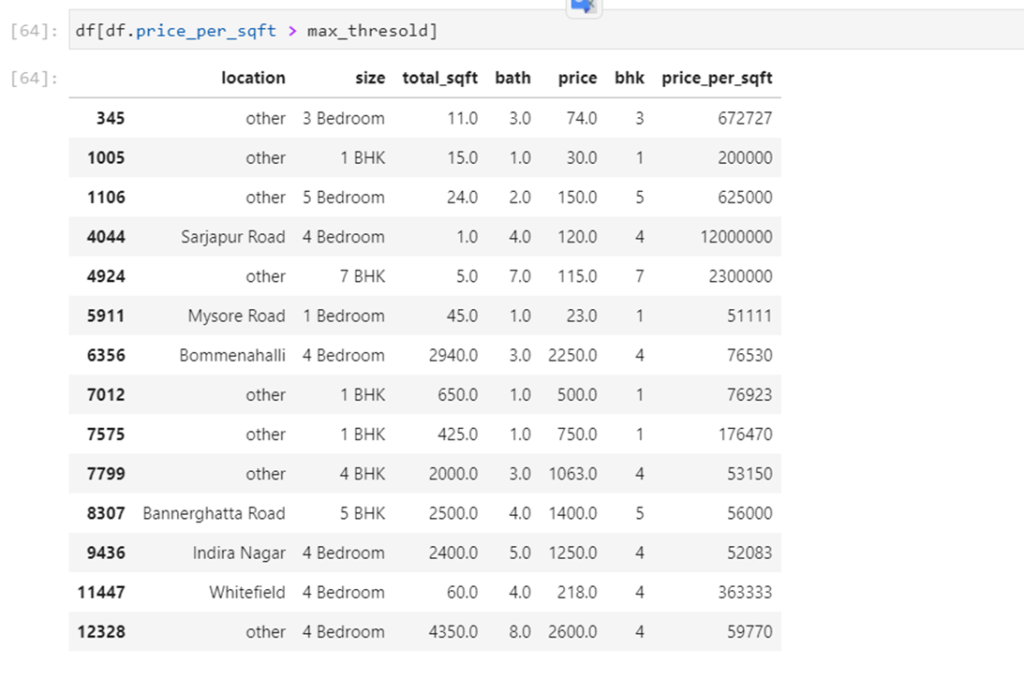
Hãy loại bỏ các ngoại lệ khỏi tập dữ liệu này.

Mô tả bảng ngay bây giờ
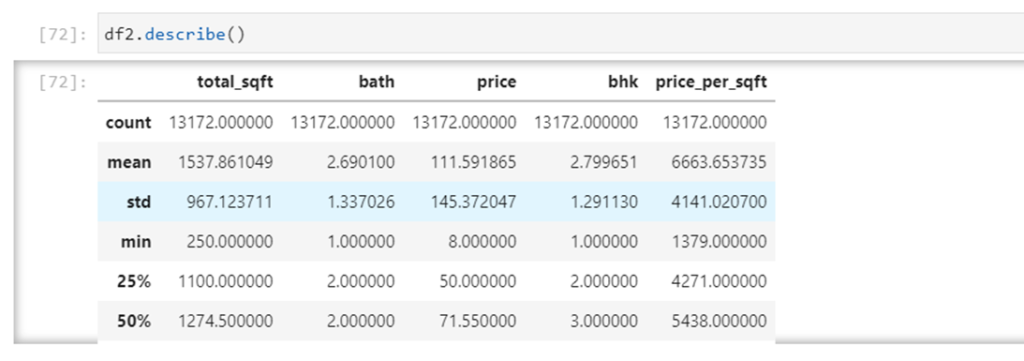

èĐây là một cách rất dễ dàng để xử lý các ngoại lệ từ tập dữ liệu giải quyết thực tế các vấn đề diễn ra trong cuộc sống học tập cũng như làm việc của chúng ta.
VI) Kết luận và đánh giá.
Bài này chúng ta đã cùng nhau làm quen với khái niệm, có thể mới với một số bạn, là Outliers. Cùng với đó là những lợi ích cũng như cách để xác định và loại bỏ những Outliers không mong muốn.
=>>Từ đó chúng ta ưu điểm và khuyết điểm của các phương pháp phát hiện ngoại vi
Ưu điểm của Z-Score cũng như Extreme Value Analysis:
- Đó là một phương pháp rất hiệu quả nếu bạn có thể mô tả các giá trị trong không gian đặc trưng bằng phân phối gaussian. (Tham số)
- Việc thực hiện rất dễ dàng bằng cách sử dụng thư viện pandas và scipy.stats.
Khuyết điểm của Z-Score:
- Nó chỉ thuận tiện khi sử dụng trong không gian đặc trưng có chiều thấp, trong một tập dữ liệu có kích thước vừa và nhỏ.
- Không được khuyến nghị khi các phân phối không thể được giả định là tham số.
Ưu điểm của Dbscan:
- Đây là một phương pháp siêu hiệu quả khi không thể giả định được sự phân bố của các giá trị trong không gian đặc trưng.
- Hoạt động tốt nếu không gian tính năng để tìm kiếm ngoại lệ là nhiều chiều (tức là 3 chiều trở lên)
- Cách triển khai của Sci-kit learning rất dễ sử dụng và tài liệu thì tuyệt vời.
- Hình dung kết quả rất dễ dàng và bản thân phương pháp này rất trực quan.
Khuyết điểm của Dbscan:
- Các giá trị trong không gian đối tượng cần được điều chỉnh tỷ lệ tương ứng.
- Việc chọn các tham số eps, MinPts và metric tối ưu có thể khó khăn vì nó rất nhạy cảm với bất kỳ tham số nào trong số ba tham số.
- Đây là một mô hình không được giám sát và cần được hiệu chỉnh lại mỗi khi một lô dữ liệu mới được phân tích.
- Nó có thể dự đoán sau khi được hiệu chỉnh nhưng thực sự không được khuyến khích.
Ưu điểm của Rừng cách ly:
- Không cần phải điều chỉnh tỷ lệ các giá trị trong không gian đối tượng địa lý.
- Đây là một phương pháp hiệu quả khi không thể giả định phân phối giá trị.
- Nó có ít tham số, điều này làm cho phương pháp này khá mạnh mẽ và dễ tối ưu hóa.
- Việc triển khai Scikit-Learn rất dễ sử dụng và tài liệu thì tuyệt vời.
Khuyết điểm của Rừng cách ly:
- Việc triển khai Python chỉ tồn tại trong phiên bản phát triển của Sklearn.
- Hình dung kết quả rất phức tạp.
- Nếu không được tối ưu hóa một cách chính xác, thời gian đào tạo có thể rất lâu và tốn kém về mặt tính toán.
èChúng ta đang sống trong một thế giới mà dữ liệu ngày càng lớn hơn theo từng giây. Giá trị của dữ liệu có thể giảm dần theo thời gian nếu không được sử dụng đúng cách. Việc tìm kiếm các điểm bất thường trực tuyến trong luồng hoặc ngoại tuyến trong tập dữ liệu là rất quan trọng để xác định các vấn đề trong kinh doanh hoặc xây dựng giải pháp chủ động để có khả năng phát hiện ra vấn đề trước khi nó xảy ra hoặc thậm chí trong giai đoạn phân tích dữ liệu khám phá (EDA) để chuẩn bị tập dữ liệu cho ML .
Nguồn thao khảo:
https://laptrinhx.com/outlier-detection-and-removal-using-a-percentile-1009251500/
Video demo: